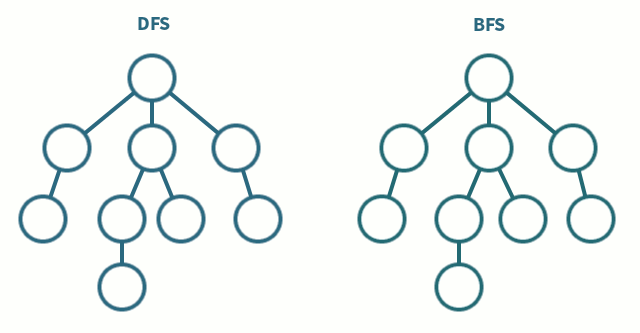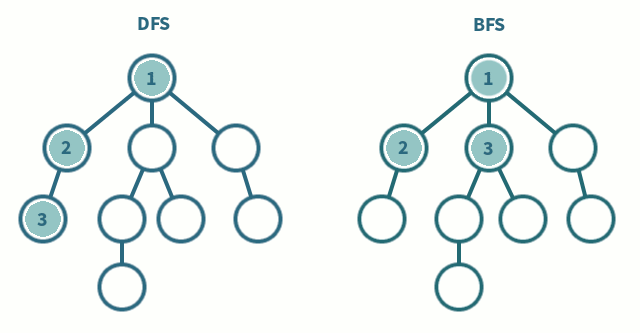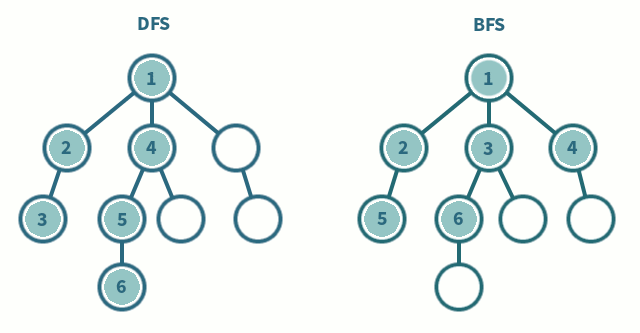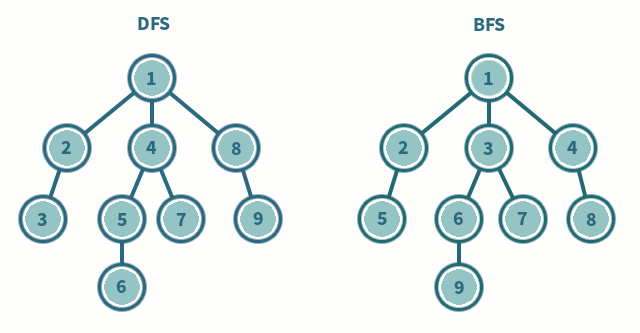
파이썬에서 "enumerate" 함수는 반복 가능한 객체를 인자로 받아서 해당 객체의 요소들을 순회하면서, 각 요소의 인덱스와 값을 순서쌍으로 반환한다.
이러한 기능을 통해 코드 작성의 편의성과 가독성을 높일 수 있다.
enumerate(iterable, start=0)
iterable: 반복 가능한(iterable) 객체, 예를 들면 리스트(list), 튜플(tuple), 문자열(str), 딕셔너리(dictionary) 등이 있다.
start: 인덱스의 시작값을 설정합니다. 기본값은 0이다.
예제
다음과 같은 리스트가 있다.
fruits = ['apple', 'banana', 'cherry']
이 리스트를 "enumerate" 함수에 전달하면, 다음과 같은 enumerate 객체가 반환된다.
enumerate_fruits = enumerate(fruits)
이제 이 객체를 for 루프로 반복하면, 인덱스와 해당 요소값을 순서대로 출력할 수 있다.
for index, fruit in enumerate_fruits:
print(index, fruit)
위의 코드를 실행하면 다음과 같은 결과가 출력다.
0 apple
1 banana
2 cherry
enumerate와 for 루프
"enumerate" 함수는 주로 for 루프와 함께 사용된다.
for 루프는 반복 가능한(iterable) 객체를 순회하면서, 각 요소를 처리하는데, 이 때 "enumerate" 함수를 사용하면 인덱스 정보를 함께 처리할 수 있기 때문에 유용하다.
for index, fruit in enumerate(fruits):
print(f"Index {index}: {fruit}")
위 코드는 fruits 리스트의 요소를 순회하면서, 각 요소의 인덱스와 값을 출력한다.
결론
"enumerate" 함수는 파이썬에서 매우 유용한 내장 함수 중 하나이다.
이 함수는 반복 가능한(iterable) 객체를 인자로 받아서 해당 객체의 요소들을 순회하면서, 각 요소의 인덱스와 값을 순서쌍으로 반환한다. 이러한 기능을 통해 코드 작성의 편의성과 가독성을 높일 수 있다. "enumerate" 함수는 for 루프와 함께 사용되며, for 루프를 사용할 때 인덱스 정보를 함께 처리할 때 유용하다. 이 함수를 사용하면 코드 작성이 더욱 간결해지고 가독성이 좋아진다.
collections모듈은 파이썬에서 일반적으로 제공되고 있는 dict, list, set, tuple의 대안을 제공해주는 특별한 데이터 컨테이너들의 집합이다.
큐를 이용하는 구현을 할 때 사용하는 deque 역시 collections 모듈에서 사용할 수 있다.
collections 모듈에는 활용도 높아 보이는 container들이 많이 보였는데 오늘은 그중 Counter에 대해 공부해 보았다.
1. Counter
Counter는 해시 가능한 객체를 세는 데 사용하는 딕셔너리 서브 클래스이다.
여기서 해시란 다양한 길이를 가진 데이터를 고정된 길이를 가진 데이터로 매핑한다는 것이다. (이를 이용하여 특정한 배열의 인덱스나 위치, 위치를 입력하여 데이터의 값을 지정하거나 찾을 수 있다.)
즉, 해시 가능한 객체라는 의미는 고정된 길이를 가진 데이터로 매핑이 가능한 데이터라는 뜻이고, 파이썬에서는 보통 Immutable 한 객체를 해시 가능한 객체라고 한다. 정리하자면, Counter는 해시 가능한 객체(Immutable 한 객체)를 세어주는 딕셔너리의 서브 클래스이다.
리스트(list), 딕셔너리(dict), 집합(set) 등은 변경 가능한(mutable) 객체이다.
해시 가능한 객체: 정수, 부동 소수점, 문자열, 튜플 등 변경 불가능한 객체
해시 불가능한 객체: 리스트, 딕셔너리, 집합 등 변경 가능한 객체
1.2 Counter 사용법
위에서 설명한 것처럼 Counter는 해시가능한 객체 요소가 딕셔너리 키로 저장되고 개수가 딕셔너리의 값으로 저장된다.
여기서 개수는 0이나 음수를 포함하는 임의의 정숫값이 될 수 있다.
문자열, 리스트, 튜플 또는 다른 반복 가능한(iterable) 객체를 인수로 받아 생성할 수 있다.
from collections import Counter
# 문자열을 이용해 Counter 생성
c = Counter("hello world")
print(c)
# 출력: Counter({'l': 3, 'o': 2, 'h': 1, 'e': 1, ' ': 1, 'w': 1, 'r': 1, 'd': 1})
# 리스트를 이용해 Counter 생성
c = Counter([1, 2, 2, 3, 3, 3])
print(c)
# 출력: Counter({3: 3, 2: 2, 1: 1})
# 튜플을 이용해 Counter 객체 생성
data_tuple = (1, 2, 2, 3, 3, 3)
counter = Counter(data_tuple)
print(counter)
# 출력: Counter({3: 3, 2: 2, 1: 1})
1.3 Counter additional methods
elements()
요소의 개수만큼 반복되는 순환자료형을 반환한다.
여기서 주의할 점은 Collector 역시 Dict과 마찬가지로 순서가 존재하지 않기 때문에 처음 발견되는 순서대로 반환한다.
FIFO(First In, First Out)라고 부르기도 하며 반대로 LILO(Last In, Last Out)이라고 설명하기도 한다.
큐에서 알아두어야 할 용어가 있는데 Enqueue(인큐), Dequeue(디큐)이다.
-. Enqueue : 큐에서 데이터를 입력하는 기능
-. Dequeue : 큐에서 데이터를 꺼내는 기능
추가로 파이썬에서는 queue, deque라는 두가지 내장 모듈을 통해 큐를 구현할 수 있다.
2. queue 내장 모듈을 통한 큐 구현 - 1
파이썬에서는 queue라는 내장 모듈을 제공한다. 아래 예시로 든 그림을 통해 코드를 작성해보았다.
put( )은 큐에 데이터를 넣을 때 사용하는 메서드, get( )은 큐에서 데이터를 꺼내는 메서드이다
<코드>
import queue
#큐 모듈의 큐 클래스 객체 선언
data = queue.Queue()
print(type(data))
#선언 된 큐 객체에 3개 데이터 입력하기 : 2,5,8
data.put(2)
data.put(5)
data.put(8)
#큐 객체에서 입력된 객체 하나씩 꺼내기 :FIFO
print(data.get())
print(data.get())
print(data.get())
<결과>
<class 'queue.Queue'>
2
5
8
숫자 2,5,8을 순서대로 넣고 get( )을 3번 하면 먼저 입력 된 순서대로 출력된다.
queue 내장 모듈 내에는 기본적인 Queue( ) 클래스 외에도 LifoQueue( ), PriorityQueue( ) 클래스가 존재한다. 여기서 자세히 다루진 않겠지만 LifoQueue( )는 스택과 같은 LIFO 구조, PriorityQueue( ) 는 사용자가 우선순위를 지정한대로 데이터를 꺼낼 수 있는 구조라고 보면 될 것 같다.
2. deque 내장 모듈을 통한 큐 구현 - 2
큐를 구현할려면 위의 예시처럼 queue 를 호출해도 되지만, 일반적으로 deque를 사용하여 큐를 구현하는 것을 추천한다.
append(): 큐의 끝에 요소를 추가
popleft(): 큐의 맨 앞에서 요소를 제거하고 반환
from collections import deque
queue = deque()
# 큐에 요소 추가 (enqueue)
queue.append(1)
queue.append(2)
queue.append(3)
print(queue) # deque([1, 2, 3])
# 큐에서 요소 제거 (dequeue)
front_element = queue.popleft()
print(front_element) # 1
print(queue) # deque([2, 3])
deque의 장점
양방향 작업의 효율성:
deque는 리스트와 달리 양쪽 끝에서 요소를 추가하거나 제거할 때 O(1)의 시간 복잡도를 가진다.
리스트는 한쪽 끝에서만 O(1)의 시간 복잡도를 가지며, 다른 쪽 끝에서는 O(n)의 시간 복잡도를 가진다.
유연성:
deque는 스택과 큐의 모든 연산을 효율적으로 지원하므로, 상황에 따라 스택과 큐의 역할을 모두 수행할 수 있다.
deque의 주요 메서드
스택 연산
append(x): 스택의 맨 위에 요소 x를 추가
pop(): 스택의 맨 위에서 요소를 제거하고 반환
큐 연산
append(x): 큐의 끝에 요소 x를 추가
popleft(): 큐의 맨 앞에서 요소를 제거하고 반환
기타 메서드
appendleft(x): 큐의 맨 앞에 요소 x를 추가
popright(): 큐의 맨 끝에서 요소를 제거하고 반환
이와 같이 deque는 스택과 큐의 역할을 모두 효율적으로 수행할 수 있는 강력한 자료 구조이다.
deque와 queue 모듈의 비교
용도:
deque: 양방향에서 빠른 삽입 및 삭제가 필요한 경우에 사용된다. 큐와 스택의 연산을 모두 효율적으로 수행할 수 있다.
queue 모듈: 멀티스레딩 환경에서 안전하게 큐를 사용해야 하는 경우에 사용된다. 특히, 스레드 간의 작업을 조정할 때 유용하다.
성능:
deque: 대부분의 큐 및 스택 연산이 O(1)로 매우 효율적이다.
queue 모듈: 멀티스레딩을 지원하기 위해 추가적인 동기화가 필요하므로 약간의 성능 오버헤드가 있을 수 있다.
사용 편의성:
deque: 단순한 큐 및 스택 연산을 수행할 때 간단하고 직관적인 인터페이스를 제공한다.
queue 모듈: 멀티스레딩 환경에서 안전하게 사용할 수 있지만, 단일 스레드 환경에서는 다소 복잡할 수 있다.
결론
일반적인 큐 또는 스택 기능이 필요하고 단일 스레드 환경에서 사용한다면 collections.deque를 사용하는 것이 좋다.
멀티스레딩 환경에서 안전하게 큐를 사용해야 한다면 queue 모듈을 사용하는 것이 적합하다.
해시/해쉬(Hash)는 해시 테이블로 Key, Value를 매핑해서 데이터를 저장하는 자료구조이다.
파이썬에서는 기본적으로 제공되는 딕셔너리 자료형이 해시 테이블과 같은 구조이다.!
용어
키(Key) - 고유의 값으로 해시 함수의 Input, 다양한 길이의 값이 될 수 있다.
해시테이블(Hash Table) 또는 해시 맵(Hash Map) - Key와 Value를 매핑해서 데이터를 저장하는 자료구조
해시 함수(Hash Function) - 임의의 값을 고정된 길이의 데이터로 변환하는 함수. 다양한 길이의 키를 고정된 길이의 해시로 변환시키므로 저장소를 효율적으로 운영
해시(Hash) - 해시함수의 Output으로 해시값과 매칭되어 버킷에 저장
해시 값(Hash Value) 또는 해시 주소(Hash Address) - Key에 해시함수를 적용하여 얻는 해시 값
버킷(Bucket) - 한 개의 데이터를 저장할 수 있는 공간
다양한 길이를 갖고있는 키 값에 해시 함수를 적용시키면 00, 01, 02 등과 같이 고정된 길이의 데이터로 변환한다. 이렇게 변환된 데이터가 해시 값이고 버킷에는 키와 매핑된 원래 데이터를 저장한다. 결과적으로 변환된 키값과 버킷에 매핑되어 있는 데이터를 해시라 하고이러한 자료구조를 해시 테이블 이라 한다.
해시 언제 사용하면 좋을까?!
해시를 사용하면 좋을 때를 소개해드리고자 합니다 : )
1. 리스트를 쓸 수 없을 때
리스트는 숫자 인덱스를 이용하여 원소에 접근하는데 즉 list[1]은 가능하지만 list['a']는 불가능합니다.
인덱스 값을 숫자가 아닌 다른 값 '문자열, 튜플'을 사용하려고 할 때 딕셔너리를 사용하면 좋습니다.
2. 빠른 접근 / 탐색이 필요할 때
아래에서 표로 정리해 보여드릴 예정이지만, 딕셔너리 함수의 시간복잡도는 대부분 O(1)이므로 아주 빠른 자료구조 입니다!
3. 집계가 필요할 때
원소의 개수를 세는 문제는 코딩 테스트에서 많이 출제되는 문제입니다. 이때 해시와, collections 모듈의 Counter 클래스를 사용하면 아주 빠르게 문제를 푸실 수 있을 것입니다.
딕셔너리와 리스트의 시간 복잡도 차이
아까 위에서 딕셔너리의 시간 복잡도는 대부분 O(1)을 갖는다고 말씀드렸는데 리스트와 시간복잡도를 비교해보도록 하겠습니다.
Operation
Dictionary
List
Get Item
O(1)
O(1)
Insert Item
O(1)
O(1) ~ O(N)
Update Item
O(1)
O(1)
Delete Item
O(1)
O(1) ~ O(N)
Search Item
O(1)
O(N)
List에 비해 Dictionary가 매우 빠른 시간복잡도를 갖는 것을 보실 수 있습니다.
즉 , 원소를 넣거나 삭제, 찾는 일이 많을 때에는 딕셔너리를 사용하는 것이 좋습니다
※ 파이썬 3.7 이상부터 딕셔너리는 원소가 들어온 순서를 보장합니다. 반면, 3.7 미만은 순서를 보장하지 않습니다. 딕셔너리를 이용해 문제를 풀 때에는 버전에 유의하세요.
Dictionary 사용법
📌 Init
{}를 사용하거나 dict함수 호출 시 빈 딕셔너리를 선언할 수 있습니다.
key - value 쌍을 갖는 dictionary 선언도 바로 가능합니다.
# 빈딕셔너리 생성
dict1 = {} # {}
dict2 = dict() # {}
# 특정 key-value쌍을 가진 dictionary 선언
Dog = {
'name': '동동이',
'weight': 4,
'height': 100,
}
'''
{'height': 100, 'name': '동동이', 'weight': 4}
'''