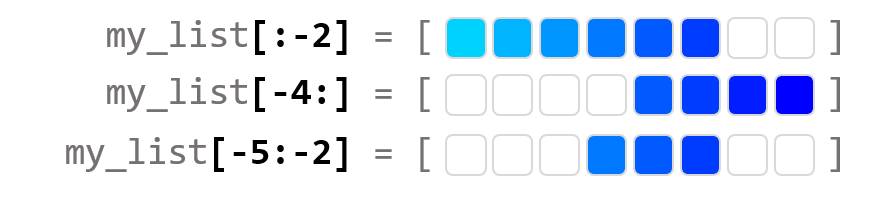
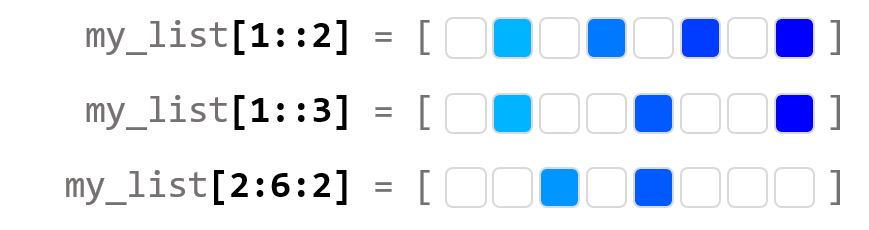
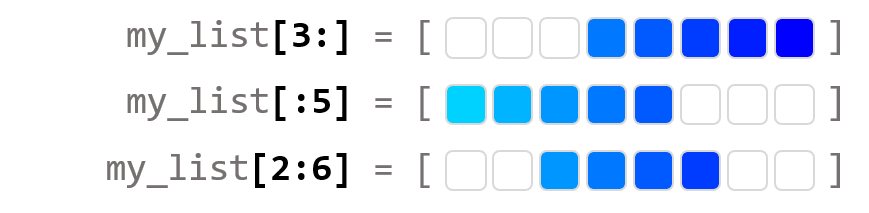✅ Python ASCII
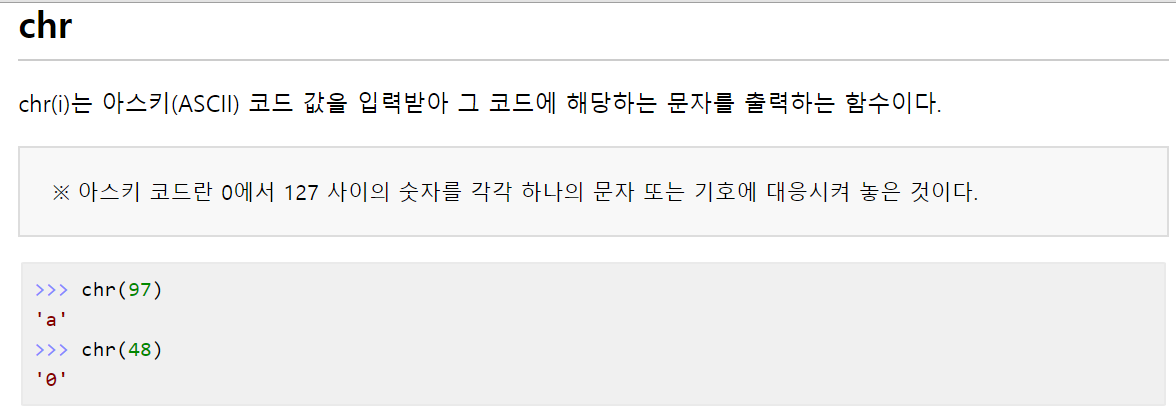
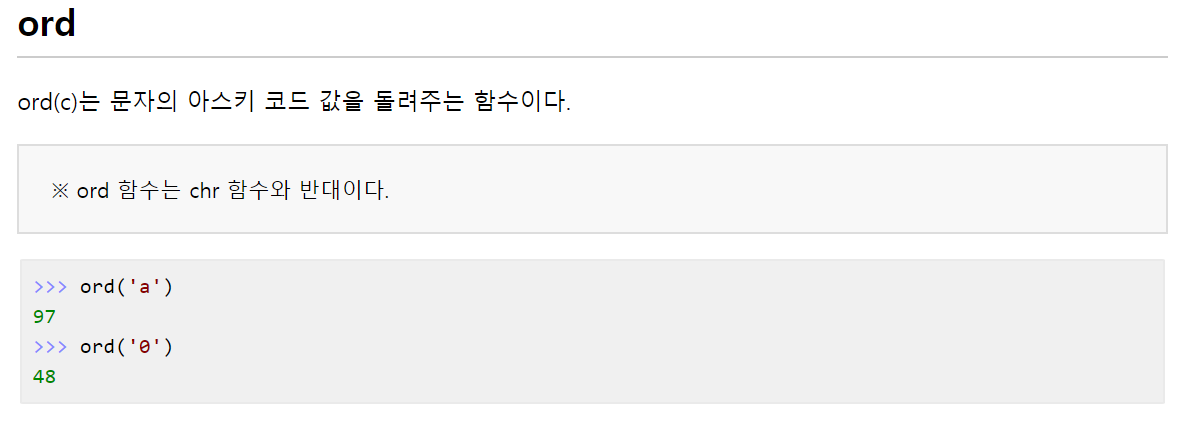
- ord(문자) : 문자에 해당하는 ASCII 정수값 반환
- chr(정수) : 정수에 해당하는 ASCII 문자 반환
- string.ascii_lowercase : 소문자에 해당하는 ASCII 값
- string.ascii_uppercase : 대문자에 해당하는 ASCII 값
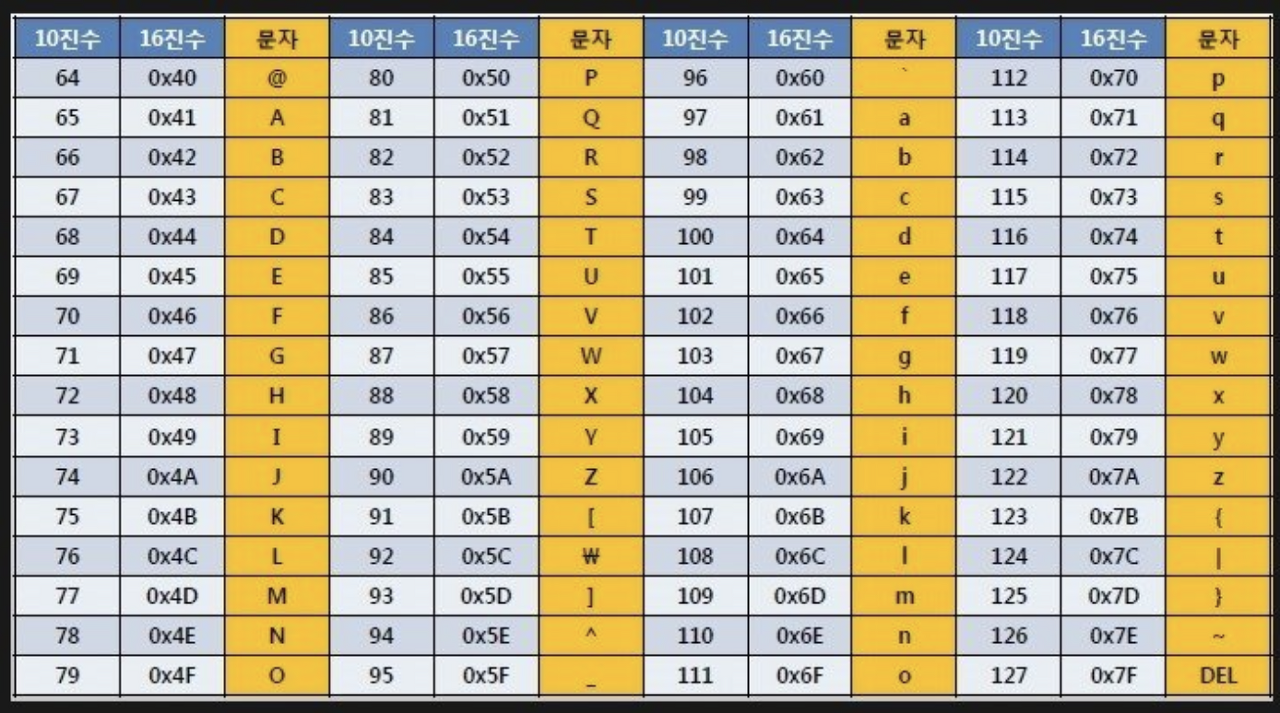
✅ ASCII Chart
✅ 코드 설명
파이썬의 내장함수가 있다.
- ord(문자) : 해당 문자의 ASCII 정수값 반환
- chr(정수) : 해당 정수의 ASCII 문자 반환
- string.ascii_lowercase : 소문자 ASCII 값
- string.ascii_uppercase : 대문자 ASCII 값
파이썬에서 아스키코드로 변환하는 방법을 찾아보다가 이 4가지 방법을 알게 되었다.
나는 ord(), chr() 함수에 대해 설명하고자 한다.
(1) 문자열 탐색 및 공백 처리
def solution(s, n):
answer = ''
for i in s:
if i == " ":
answer += " "문자열 s를 보고 문자 하나씩 탐색해나간다.
만약, i(문자)가 공백문자열이라면, 결과에 공백 문자열을 더해준다.
(2) 아스키코드 처리
def solution(s, n):
answer = ''
for i in s:
if i == " ":
answer += " "
else:
k = chr(ord(i) + n)
if k.isupper() != i.isupper() or not k.isalpha():
k = chr(ord(k) - 26)
answer += k
return answer- 만약 문자가 공백이 아닐 경우 (else문으로 들어온다.)
- 임시 변수 k에 i의 아스키 코드값을 구한 후 n을 더해주고 이를 다시 문자로 변환한다.
-> k = 임시 변수
-> ord(k) + n : k의 아스키 코드 값에 n을 더해줌.
-> chr(ord(k) + n) : 다시 문자로 바꾸어줌.
- 임시변수 k에는 두가지 상황이 있을 수 있다. -> else 문 내에 if 문으로 처리
(1) k가 특수문자인 경우 (대소문자의 범위에서 벗어남)
(2) 기존 문자는 대문자이지만, n을 더한 k가 소문자가 된 경우
-> 아스키코드 표에서 문자 = Z, n =10인 경우를 생각하면 된다.
(처리방법)
- 만약 현재 문자 i는 대문자인데, k가 소문자인 경우, 또는 k가 알파벳이 아닌 경우
-> k에서 26(알파벳의 개수)만큼 빼서 해결할 수 있다.
-> i = Z, n = 10일 때를 생각해보자.
-> i에 n을 더하면 k는 d가 된다. 이때 k.isalpha는 참이지만, 앞 조건이 거짓이 된다.
-> k에서 26을 빼 주면 J가 된다.
-> Z에서 10을 더하면 J가 된다!!!
'Python' 카테고리의 다른 글
| [Python] - 자료구조 : 스택(Stack) 개념 및 사용 (0) | 2023.02.13 |
|---|---|
| [Python] - 산술연산자 7가지 ( +, -, *, /, **, //, %) (0) | 2023.02.11 |
| [Python] - 리스트 값 삭제 clear, pop, remove, del (0) | 2023.02.03 |
| [Python] - 파이썬 진수변환(2진법, 3진법, 5진법, 10진법).. [n진법] (0) | 2023.02.02 |
| [Python] - 파이썬 리스트 슬라이싱 (0) | 2023.01.29 |