※ DFS/BFS를 알기 전에 밑에 글부터 읽고오자!
https://veggie-garden.tistory.com/28
** DFS & BFS
* DFS(Depth First Search)란? == 깊이 우선 탐색
자료의 검색, 트리나 그래프를 탐색하는 방법. 한 노드를 시작으로 인접한 다른 노드를 재귀적으로 탐색해가고 끝까지 탐색하면 다시 위로 와서 다음을 탐색하여 검색한다.
- dfs는 그래프의 노드를 갈 수 있는 데 까지 끝까지 방문하는 것이다. ==> 그래프에서 깊은 부분을 우선적으로 탐색하는 알고리즘
- 노드를 순서대로 목적지에 도달할 때 까지 방문하면서, 각 노드에서 또 방문할 수 있는 위치를 저장해 둔다.
- 노드가 끝까지 갔다가 다시 한칸 뒤로 돌아와, 갈 수 있는 방향을 탐색한다.
- 정리하면 특정한 경로로 탐색하다가 특정한 상황에서 최대한 깊숙이 들어가서 노드를 방문한 후, 다시 돌아가 다른 경로로 탐색하는 알고리즘
- 따라서 재귀적이고 / 스택을 이용할 수 있다. ==> 스택 자료구조 이용
* BFS(Breadth First Search)란? == 너비우선탐색
자료의 검색, 트리나 그래프를 탐색하는 방법. 한 노드를 시작으로 인접한 다른 노드를 재귀적으로 탐색해가고 끝까지 탐색하면 다시 위로 와서 다음을 탐색하여 검색한다.
- bfs는 노드에서 인접한 노드를 먼저 방문한다. ==> 가까운 노드부터 탐색하는 알고리즘
- 한 노드에서 갈수있는 모든 경우의 수를 저장한 후, 순서대로 방문한다.
- 이를 반복하기 위해서 큐를 사용한다. ==> 선입선출 방식인 큐 자료구조를 이용
- 큐에 방문할 위치를 저장함으로써 순서대로 방문이 가능하다.
* DFS vs BFS
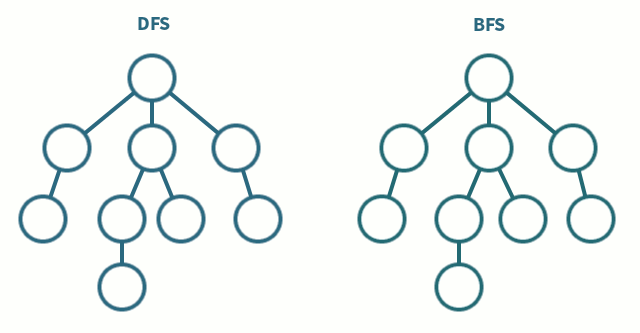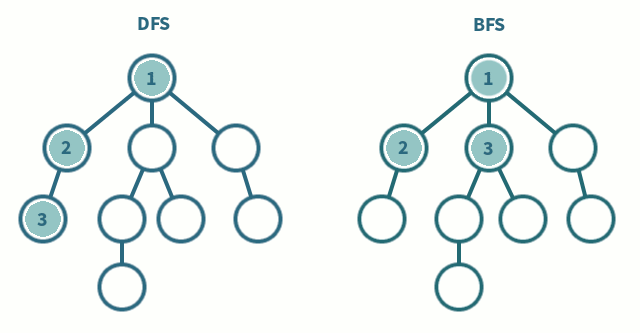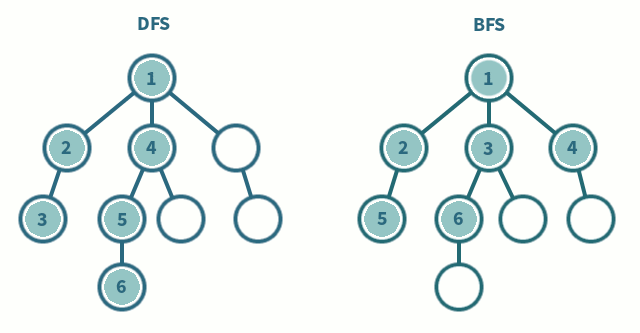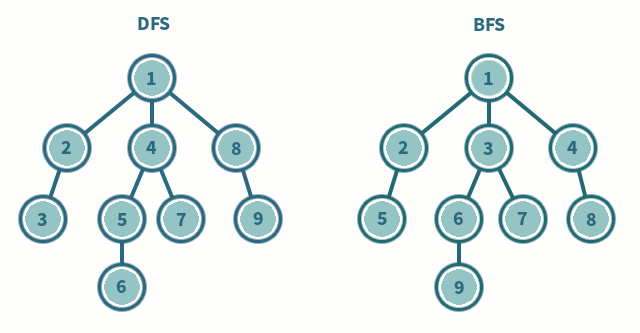
출처: https://iq.opengenus.org/dfs-vs-bfs/
DFS와 BFS의 차이점은 바로 노드 방문 순서이다.
- BFS : 너비우선탐색
: 동작 방식
1. 탐색 시작 노드를 큐에 삽입하고 방문 처리를 한다.
2. 큐에서 노드를 꺼내 해당 노드의 인접 노드 중에서 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리를 한다.
3. 2번의 과정을 더 이상 수행할 수 없을 때까지 반복한다.
: 탐색 소요 시간 : O(N)
- DFS : 깊이 우선 탐색
: 동작 방식
1. 탐색 시작 노드를 스택에 삽입하고 방문처리한다.
2. 스택의 최상단 노드에 방문하지 않은 인접 노드가 있으면, 그 인접 노드를 스택에 넣고 방문처리를 한다. 방문하지 않은 인접 노드가 없으면 스택에서 최상단 노드를 꺼낸다.
3. 2번의 과정을 더 이상 수행할 수 없을 때까지 반복한다.
>> 방문 처리는 스택에 한번 삽입되어 처리된 노드가 다시 삽입되지 않게 체크하는 것. 방문처리를 함으로써 각 노드를 한번씩만 처리할 수 있다.
- 그래프를 표현하는 2가지 방법
1. 인접행렬 ( Adjacency Matrix )
: 2차원 배열로 그래프의 연결 관계를 표현하는 방식
: 메모리가 불필요하게 낭비됨
: 정보를 얻는 속도가 빠르다
2. 인접리스트 ( Adjacency List )
: 리스트로 그래프의 연결 관계를 표현하는 방식
: 메모리를 효율적으로 사용 ( 연결된 정보만을 저장 )
: 정보를 얻는 속도 느림 ( 연결된 데이터를 하나씩 확인해야하기 때문 )
==> 파이썬에서는 단순히 2차원 리스트를 이용하면 된다!
파이썬은 기본 자료형인 리스트 자료형이 append()와 메소드를 제공하기 때문!
** 실습
DFS와 BFS에 대해 더 이해하기 위해서는 직접 관련 코드를 보면서 연습해봐야한다.
나는 밑에 글을 참고하면서 코드 연습을 했기에 따로 작성은 하지 않을거고 밑에 글을 참고하면서 연습하면 될 듯하다.
'Python' 카테고리의 다른 글
| [Python] collections - Counter (0) | 2024.07.06 |
|---|---|
| Python - Set() (0) | 2023.03.04 |
| [Python] 자료구조 : 큐(Queue) 개념 및 사용 (0) | 2023.02.18 |
| [Python] 자료구조 : 해시(Hash) 개념 및 사용 (0) | 2023.02.17 |
| [Python] - 자료구조 : 스택(Stack) 개념 및 사용 (0) | 2023.02.13 |