
위 그림과 같이 1부터 8까지 여덟 개의 숫자를 포함하는 하나의 리스트가 있습니다.
파이썬에서는 아래와 같이 start, stop, step 세 개의 숫자를 사용해서 리스트를 다양하게 슬라이싱할 수 있습니다.

- start를 입력하지 않으면 0을 입력한 것과 같습니다.
- stop을 입력하지 않으면 리스트의 길이 (len(my_list))를 입력한 것과 같습니다.
- step을 입력하지 않으면 1을 입력한 것과 같습니다.

예제
my_list = [1, 2, 3, 4, 5, 6, 7, 8]
print(my_list[3:])
print(my_list[:5])
print(my_list[2:6])
[4, 5, 6, 7, 8]
[1, 2, 3, 4, 5]
[3, 4, 5, 6]
my_list[3:]은 리스트의 인덱스 3의 위치에서 끝까지 슬라이싱합니다.
앞에서 3개의 성분을 제외하는 것과 같습니다.
my_list[:5]은 리스트의 처음부터 인덱스 5의 위치까지 슬라이싱합니다.
앞에서 5개의 성분을 선택하는 것과 같습니다.
my_list[2:6]은 리스트의 인덱스 2의 위치에서 인덱스 6의 위치까지 슬라이싱합니다.
앞에서 6개를 선택하고 2개를 제외하는 것과 같습니다.
2) 음의 인덱스 사용하기

예제
my_list = [1, 2, 3, 4, 5, 6, 7, 8]
print(my_list[:-2])
print(my_list[-4:])
print(my_list[-5:-2])
[1, 2, 3, 4, 5, 6]
[5, 6, 7, 8]
[4, 5, 6]
my_list[:-2]은 리스트의 처음부터 인덱스 -2의 위치까지 슬라이싱합니다.
뒤에서 2개의 성분을 제외하는 것과 같습니다.
my_list[-4:]은 리스트의 인덱스 -4의 위치에서 끝까지 슬라이싱합니다.
뒤에서 4개의 성분을 선택하는 것과 같습니다.
my_list[-5:-2]은 리스트의 인덱스 -5의 위치에서 인덱스 -2의 위치까지 슬라이싱합니다.
뒤에서 5개를 선택하고 2개를 제외하는 것과 같습니다.
3) 리스트 복사하기

예제
my_list = [1, 2, 3, 4, 5, 6, 7, 8]
print(my_list[:])
[1, 2, 3, 4, 5, 6, 7, 8]
my_list[:]은 리스트의 처음부터 끝까지 슬라이싱합니다.
리스트 전체를 복사하는 것과 같으며, 얕은 복사 (Shallow copy)에 해당합니다.
4) 간격 (step) 사용하기

예제
my_list = [1, 2, 3, 4, 5, 6, 7, 8]
print(my_list[::2])
print(my_list[::3])
[1, 3, 5, 7]
[1, 4, 7]
my_list[::2]은 리스트의 처음부터 끝까지 간격 2 단위로 슬라이싱합니다.
my_list[::3]은 리스트의 처음부터 끝까지 간격 3 단위로 슬라이싱합니다.
5) 시작 (start)/끝 (stop)/간격 (step) 사용하기

예제
my_list = [1, 2, 3, 4, 5, 6, 7, 8]
print(my_list[1::2])
print(my_list[1::3])
print(my_list[2:6:2])
[2, 4, 6, 8]
[2, 5, 8]
[3, 5]
my_list[1::2]은 리스트의 인덱스 1의 위치에서 끝까지 간격 2 단위로 슬라이싱합니다.
my_list[1::3]은 리스트의 인덱스 1의 위치에서 끝까지 간격 3 단위로 슬라이싱합니다.
my_list[2:6:2]은 리스트의 인덱스 2의 위치에서 인덱스 6의 위치까지 간격 2 단위로 슬라이싱합니다.
6) 음의 간격 (step) 사용하기
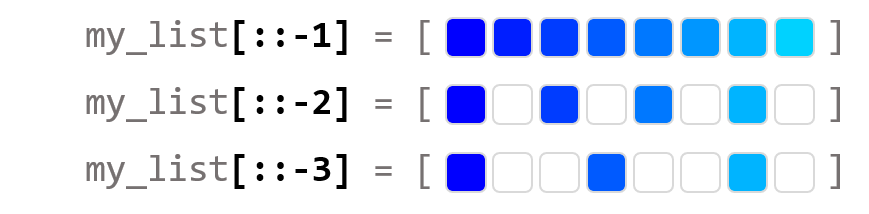
예제
my_list = [1, 2, 3, 4, 5, 6, 7, 8]
print(my_list[::-1])
print(my_list[::-2])
print(my_list[::-3])
[8, 7, 6, 5, 4, 3, 2, 1]
[8, 6, 4, 2]
[8, 5, 2]
my_list[::-1]은 리스트의 처음부터 끝까지 간격 -1 단위로 슬라이싱합니다.
뒤집어진 리스트 전체를 복사하는 것과 같습니다.
마찬가지로 my_list[::-2]은 리스트의 처음부터 끝까지 간격 -2 단위로 슬라이싱합니다.
my_list[::-3]은 리스트의 처음부터 끝까지 간격 -3 단위로 슬라이싱합니다.
전체 내용은 아래 그림을 참고하세요.

'Python' 카테고리의 다른 글
| [Python] - 문자열(string) <-> 리스트(list) 변환 (0) | 2023.02.03 |
|---|---|
| [Python] - 파이썬 진수변환(2진법, 3진법, 5진법, 10진법).. [n진법] (0) | 2023.02.02 |
| [Python] 자료구조 : 덱(deque()) 개념 및 사용 (0) | 2023.01.29 |
| [python] 삼항연산자 ( if-else 삼항표현식 ) - if 조건식을 한줄로 표현 (0) | 2023.01.29 |
| [python] count( ) 문자열의 개수, 리스트의 개수 세는 함수 (1) | 2023.01.29 |
