728x90
3월 25일 월요일 학습 내용
객체지향
- 객체들의 모임으로 파악하고자 하는 것
- 각각의 객체는 메시지를 주고받고, 데이터를 처리할 수 있음
- 객체지향 관점에서의 서점
- 책을 관리하는 것은? <책장>
- 손님을 관리하는 것은? <방명록>
- 돈을 관리하는 것은? <금고>
객체 지향 프로그래밍
- 객체 지향 프로그래밍은 컴퓨터 프로그래밍의 패러다임 중 하나이다.
- “객체”들의 모임으로 파악하고자 하는 것
→ 각각의 객체는 메시지를 주고받고, 데이터를 처리할 수 있다. - 클래스 class
- 오브젝트 object
- 인스턴스 instance
- 참조형 변수 reference variable
- 핵심 : 메시징 => 객체가 어떻게 해야 하는가가 아니라 무엇을 해야하는가를 설명한다는 것 (메소드)
final 키워드
- 변수(variable), 메서드(method), 또는 클래스(class)에 사용 가능
- 변수에 final을 붙이면 이 변수는 수정할 수 없다는 의미
- 메서드에 final을 붙이면 override를 제한
- final 키워드를 클래스에 붙이면 상속 불가능 클래스
접근제한자
- public, protected, package, private가 있다.
- public : 외부 클래스가 자유롭게 사용할 수 있도록 한다.
- protected : 같은 패키지 또는 자식 클래스에서 사용할 수 있도록 한다.
- default**(**package) : 같은 패키지에서 사용할 수 있도록 한다.
- private : 외부 클래스에서 사용할 수 없도록 한다.접근제한자

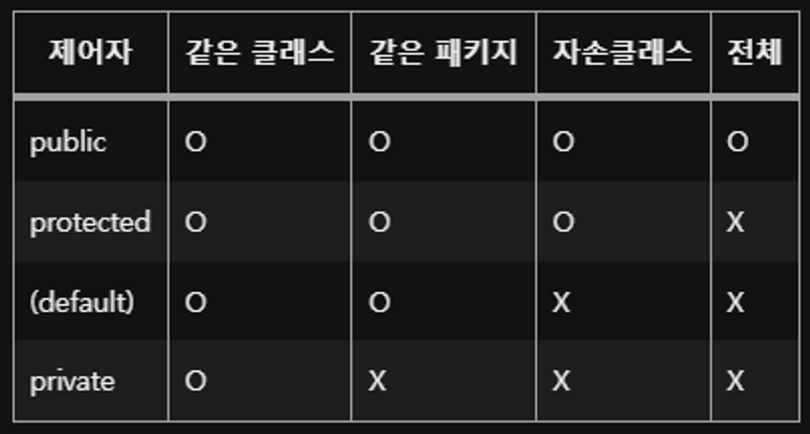
- package안의 하위 package가 있더라고 다른 package로 보기 때문에 사용하고자하는 package를 import 해줘야한다.
<예시 코드>
- com.example.util 패키지 안에 있는 Calculator 클래스
package com.example.util;
public class Calculator {
public int plus(int a, int b){
return a+b;
}
public int minus(int a, int b){
return a-b;
}
}- com.example.main 패키지 안에 있는 CalculatorTest 클래스
package com.example.main;
// util 패키지에 있는 클래스를 사용하기 위해 import
import com.example.util.Calculator;
public class CalculatorTest {
public static void main(String[] args) {
Calculator cal = new Calculator();
System.out.println(cal.plus(1,5));
System.out.println(cal.minus(5,2));
}
}클래스
- 자바에서 클래스는 설계도라고 본다.
- 클래스는 필드(속성, Field)와 메소드(행위, 기능, Method)를 가진다.
- 클래스에는 객체를 생성하기 위한 필드와 메소드가 정의되어 있어야한다.
- 클래스로부터 객체를 만드는 과정을 인스턴스화라고 한다.
- 하나의 클래스로부터 여러 객체를 만들 수 있음
- 클래스로부터 만들어진 객체를 해당 클래스의 인스턴스라고 함
- main 메소드가 없는 클래스는 실행되지 않음
필드(field)
- 클래스가 가지는 속성
- 다른 언어의 경우 멤버변수라고 하는 경우도 있다.
- static 키워드가 함께 사용되는 필드를 클래스 필드, 함께 사용되지 않는 필드를 인스턴스 필드라고 한다.
필드 선언 방법
[접근제한자] [static] [final] 타입 필드명 [=초기값];
String name;
String address = "경기도 수원시";
public int age = 50;
protected boolean flag;
- 대괄호 안에 있는 내용은 생략가능하다는 뜻
- 필드의 첫번째 글자는 소문자로 시작하는 것이 관례이며, 자바의 경우 흔히 카멜 케이스로 작성
- 타입(type)은 기본형(boolean, byte, …)과 참조타입(class, 인터페이스, 배열) 등 사용가능
- 초기값이 없는 경우
- 참조형일 경우 null / boolean형일 경우 false / 나머지 기본형은 모두 0 으로 초기화된다.
- 참조형일 경우 null / boolean형일 경우 false / 나머지 기본형은 모두 0 으로 초기화된다.
클래스 선언
클래스 선언 방법
public class 클래스명 {
}- Dice 클래스와 클래스의 필드 및 메소드 선언
package com.example.util;
public class Dice {
private int face;
private int eye;
public void roll(){
eye = (int)(Math.random()*face) + 1;
}
public int getEye(){
return eye;
}
public void setFace(int face) {
this.face = face;
}
}
객체 선언
객체 선언 방법
클래스명 객체명 = new 클래스명();
// 참조타입 참조변수 new연산자 생성자- 메모리
- new 연산자를 사용할 때마다 메모리에 인스턴스가 생성.
- 인스턴스는 더 이상 참조되는 것이 없을 때, 보통 메모리 부족시 가비지 컬렉션(Garbage Collection)에 저장
- static한 필드는 클래스가 로딩될 때 딱 한번 메모리에 올라가고 초기화
- 인스턴스 메소드(static이 안붙은 메소드)는 인스턴스를 생성하고나서 레퍼런스 변 수를 이용해 사용
- 클래스 메소드는 클래스명.메소드명() 으로 사용가능
- 메소드 안에 선언된 변수들은 메소드가 실행될 때 메모리에 생성되었다가, 메소드가 종료될 때 사라짐
- DiceTest 클래스에서 Dice 클래스 객체 생성
package com.example.main;
import com.example.util.Dice;
public class DiceTest {
public static void main(String[] args) {
Dice dice = new Dice();
dice.setFace(6);
dice.roll();
int eye = dice.getEye();
System.out.println(eye);
}
}
메소드 선언
- 객체지향의 핵심은 “메시징”이다.
- 자율적인 객체는 스스로 정한 원칙에 따라 판단하고 스스로의 의지를 기반으로 행동하는 객체이다.
- 객체가 어떤 행동을 하는 이유는 다른 객체로부터 요청을 수신했기 때문이다.
메소드 선언 방법
[접근제한자][static]리턴type 메소드이름([매개변수,...]) {
실행문..
}- 메소드 이름은 소문자로 시작하는 것이 관례이다.
- 클래스의 메소드를 호출하려면
- 클래스에 대한 인스턴스를 생성하거나
- 래퍼런스 변수를 이용하여 메시지를 전송한다. (메소드 호출)
- static 메소드는 인스턴스를 생성하지 않아도 호출할 수 있다.
- 전달인자 : 메소드를 호출할 때 전달하는 실제 값
- 매개변수 : 메소드 정의 부분에 나열되어있는 변수
728x90
'Spring > Spring Boot' 카테고리의 다른 글
| Spring : S3 이미지 업로드 구현 (0) | 2024.08.23 |
|---|---|
| Docker 및 Redis 설치/설정 (0) | 2024.08.22 |
| Spring 이메일 인증 기능 구현하기 2 : 비밀번호 찾기 (0) | 2024.08.20 |
| Spring 이메일 인증 기능 구현하기 1편 : 회원가입시 이메일 인증 (0) | 2024.08.20 |
| SpringJPA : 영속성 컨텍스트, 엔티티 매핑, @OneToMany, @ManyToOne (1) | 2024.06.21 |