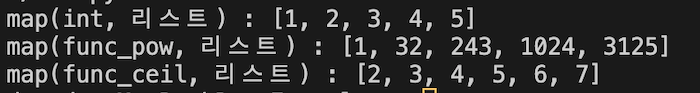원래 함수라는게 복잡한 명령들을 편하게 반복해서 사용할 수 있도록 모아두는 역할을 하는데, def 를 이용해서 다른곳에 함수를 만들고 그걸 또 호출해서 부르기까지의 수고가 필요하지 않은 그런 "가벼운? 함수"들을 위해서 만들어진게 람다 함수 입니다.
> 람다함수 선언 방법
lambda 인자: 표현식
lambda 라는 키워드를 입력하고 뒤에는 매개변수(인자)를 입력하고 콜론(:)을 넣은다음에 그 매개변수(인자)를 이용한 동작들을 적으면 됩니다. 예를 들면 인자로 들어온 값에 2를 곱해서 반환한다고 하면 lambda x : x * 2 이런식으로 됩니다. 어떤가요? 간단하죠?
> 이해를 돕기위한 람다함수와 일반함수 비교
위에서 설명했듯이 람다함수는 일반함수를 가볍게 만든 함수이기 때문에 짝수를 판별하는 함수를 만든다고 했을때 일반함수는 def is_even(x): return x % 2 == 0 이런식으로 표현을 할 수 있습니다. 이걸 람다로 표현하게 되면 is_even = lambda x : x % 2 == 0 이런식으로 표현할수 있습니다. 물론 일반함수, 람다함수 둘다 사용법은 같습니다. 이런식으로 호출을 하겠죠? is_even(1) # False is_even(2) # True
2. 파이썬 lambda 함수와 map
이미 아시는 분들은 아시겠지만 map함수는 리스트나 튜플에 어떤 특별한 처리를 할때 사용하는 함수입니다.
> map 함수의 모양과 사용법
map(함수, 리스트나 튜플)
첫번째 인자인 함수는 두번째 인자로 들어온 리스트나, 튜플에 특별한 가공 처리를 하는 함수이며, 사용자가 직접 함수를 정의해서 넣습니다. 두번째 인자인 리스트나 튜플은 바꾸고자 하는 데이터들을 집어 넣습니다.
예를들어 리스트의 모든값에 2씩 더해서 새로운 리스트를 만든다고 할때 map 함수는 아래와 같이 사용할 수 있습니다. map 의 반환값을 리스트로 다시 변경할수 있는데요 이때는 list(map(~~~)) 이런식으로 list 로 형변환해주는 함수로 감싸주면 됩니다.
# 1. 일반 함수 버전
def plus_two(x):
return x + 2
result1 = list(map(plus_two, [1, 2, 3, 4, 5]))
print(result1)
# 2. 람다 함수 버전
result2 = list(map((lambda x: x + 2), [1, 2, 3, 4, 5]))
print(result2)
> 결과
이런식으로 def를 통해서 함수를 map의 인자로 전달해줘도 되지만, map을 통해서 "리스트를 가공하는게 이번 한번 뿐이다" 라는 상황이라던지 lambda를 사용해서 간단하게 작업이 가능한 경우라면 람다 함수 사용을 고려해보는 것도 좋을듯 합니다. 여기서 이제 range와 결합하면 result3 = list(map((lambda x : x + 2), range(2, 6)) 이런식으로도 쓸 수 있습니다.
이렇게 람다 함수는 map 함수와 같이 사용자 정의 함수를 받을때 유용하게 작성할 수 있습니다. 아래 또다른 예제를 한번 볼까요?
3. python 람다 함수와 filter
filter 함수는 map 함수와 비슷하게 리스트나 튜플을 두번째인자로 받고 첫번쨰 인자로 함수를 받습니다.
> filter 함수 모양과 설명
filter(함수, 리스트나 튜플)
첫번째 인자에는 두번째 인자로 들어온 리스트나 튜플을 하나하나씩 받아서 필터링할 함수를 넣습니다. 두번쨰 인자에는 리스트나 튜플을 집어 넣습니다. 예를들어 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] 까지의 리스트가 있을때 짝수들만 filter 함수를 이용해서 리스트를 다시 만든다고 했을때, filter 함수와 람다를 이용할 수 있습니다.
# 1. 일반 함수 버전
def is_even(x):
return x % 2 == 0
result1 = list(filter(is_even, range(10))) # [0 ~ 9]
print(result1)
# 2. 람다 함수 버전
result2 = list(filter((lambda x: x % 2 == 0), range(10))) # [0 ~ 9]
print(result2)
> 결과
이때 첫번째 인자인 함수를 일반함수와 lambda 함수로 나눠서 예시를 들어보았는데요. 결과 화면을 보앗듯 filter 함수의 첫번째 인자가 True 인 경우의 값만 가지고와서 리스트를 만들었습니다. filter 함수와 람다 함수를 결합하여 깔끔하게 filter가 가능합니다.
정리
lambda (익명함수)
람다함수의 장점: 코드의 간결함, 메모리 절약
사용 방법 - lambda 인자 : 표현식
# 예시
def plus(x, y):
return x + y
plus(1, 2) # 값: 3
# 위의 함수를 람다로 표현한다면?
(lambda x,y: x + y)(1,2) #값: 3
map 함수의 반환 값은map객체 이기 때문에 해당 자료형을list 혹은 tuple로 형 변환시켜주어야합니다.
함수의 동작은두 번째 인자로 들어온 반복 가능한 자료형 (리스트나 튜플)을첫 번째 인자로 들어온 함수에 하나씩 집어넣어서 함수를 수행하는함수입니다.
>> map(적용시킬 함수, 적용할 값들)이런 식
예를 들어 첫 번째 인자가 값에 +1을 더해주는 함수라고 하고 두번째 인자에 [1, 2, 3, 4, 5] 라는 리스트를 집어넣으면
함수의 모양은 map( 값에 +1 을 더해주는 함수, [1,2,3,4,5]) 함수의 반환을 list(. )로 감싸주면 [2,3,4,5,6]이 되는 함수입니다.
1-2) map 함수를 사용하는 것과 아닌 것의 차이
똑같은 작업을 map을 이용했을 때와 그렇지 않을 때를 비교해보겠습니다.
# 리스트에 값을 하나씩 더해서 새로운 리스트를 만드는 작업
myList = [1, 2, 3, 4, 5]
# for 반복문 이용
result1 = []
for val in myList:
result1.append(val + 1)
print(f'result1 : {result1}')
# map 함수 이용
def add_one(n):
return n + 1
result2 = list(map(add_one, myList)) # map반환을 list 로 변환
print(f'result2 : {result2}')
이런 식으로 만약에 map 함수를 이용하지 않으면 for 반복문 같은걸 이용해서 일일이 하나하나 리스트 요소에 접근해서 계산을 해서 리스트에 하나씩 또 append 해주어야 하는 번거로움이 있습니다. 하. 지. 만. map 함수를 이용하면 우리는 요소에 적용할 함수 하나만 딱 넘겨준다면 알아서, 자동적으로 리스트를 함수에 적용해서 map 객체를 반환해 줍니다. 우리는 그걸 list로 형 변환해서 사용하면 됩니다.
2. map 함수 예제
2-1) 리스트와 map 함수
import math # math.ceil 함수 사용
# 예제1) 리스트의 값을 정수 타입으로 변환
result1 = list(map(int, [1.1, 2.2, 3.3, 4.4, 5.5]))
print(f'map(int, 리스트) : {result1}')
# 예제2) 리스트 값 제곱
def func_pow(x):
return pow(x, 5) # x 의 5 제곱을 반환
result2 = list(map(func_pow, [1, 2, 3, 4, 5]))
print(f'map(func_pow, 리스트) : {result2}')
# 예제3) 리스트 값 소수점 올림
result3 = list(map(math.ceil, [1.1, 2.2, 3.3, 4.4, 5.5, 6.6]))
print(f'map(func_ceil, 리스트) : {result3}')
예제 1번) 데이터 타입을 변환하는 함수를 바로 넣어 줄 수 있습니다. 첫 번째 인자로 들어간 함수가int (x)이고들어간 x의 데이터 타입을 int로 변경해주는 것이기 때문에 실수인 1.1, 2.2 등의 값이 들어가서 정수 타입으로 나오는 것을 알 수 있습니다.
예제 2번) 값의 n 제곱을 구할 수 있는함수 pow를 이용해서 들어온 리스트의 값을 5 제곱하도록 만들어 주었습니다.
예제 3번) math.ceil(x) 함수를 바로 직접 넣어줌으로써 리스트의 값을 소수점 올림 처리를 해보았습니다. 이처럼 인자가 1개인 함수는 직접 넣어줄 수 도 있습니다.
2-2) 람다와 map 함수
map의 첫 번째 인자로 함수가 들어간다면 이름 없는 함수 즉, 람다 함수도 가능하다는 뜻 아니겠습니까? 만약에 map의 인자로 사용할 함수가 일회성이거나 매우 짧은 경우에는 람다 함수를 사용해서 넘기는 게 좀 더 효율적 일 것입니다.
# map 과 lambda
# 일반 함수 이용
def func_mul(x):
return x * 2
result1 = list(map(func_mul, [5, 4, 3, 2, 1]))
print(f"map(일반함수, 리스트) : {result1}")
# 람다 함수 이용
result2 = list(map(lambda x: x * 2, [5, 4, 3, 2, 1]))
print(f"map(람다함수, 리스트) : {result2}")
이런 식으로 map 함수와 def를 이용해서 리스트의 값을 변화시킬 수도 있지만 간단+일회성 작업이라면 굳이 def를 이용할 필요 없이 map 함수와 lambda를 이용하면 좀 더 유용하게 작업을 할 수 있습니다.